운영체제 공부 4 - scheduler 3 ( 멀티프로세스 scheduler )
[ 시작하기 전에 ]
사실 이 부분만 정리를 해도 되는데 예전 내용을 복습하는 김에 앞을 설명했었다. 아마도 멀티 프로세스 환경에서의 프로그램 성능에 대한 고민은 이 부분을 이해하면 더 쉽게 할 수 있지 않을까란 막연한 생각에 시작을 했고 이 부분에 대해 설명을 하려고 한다. 약간의 정리를 하자면, 싱글 CPU 상황에서 여러 프로세스를 작업하면 생기는 문제점은 CPU 내에 있는 cache의 이점을 살리기가 어렵다는 점, 프로세스의 생성과정에서 생기는 오버헤드 그리고 프로세스가 context switch가 일어날 때의 오버헤드가 있다. 그렇다면 멀티 CPU 상황에서는 어떻게 Scheduling이 일어나야지 멀티프로세스 작동에서의 장점을 가질까?
[ 멀티 CPU 상황 ]
멀티 CPU 상황에서 여러 프로세스가 돌아가는 과정을 고민해보자. 4개의 CPU에서 5개의 프로세스가 돌아가는 경우를 생각해보자. 그리고 이 작업은 single queue로 작동을 한다고 생각을 해보자.


그러면 프로세스가 끝나고 다시 queue로 들어가고를 반복하면서 나올 수 있는 위의 상태가 가장 최악일 것이다. 위의 경우는 연속적으로 프로세스가 작동은 하지만 Cache의 이점을 하나도 살리지 못했고 context switch로 인한 비용이 지속적으로 발생하고 있다.
그러면 이런 상황에서 그나마 나은 선택을 하려면? 다음과 같이 바꾸는게 최선일 것이다.

해당 경우는 이전보다 context switch가 일어나는 상황은 적어졌고 cache의 이점을 전보다 살렸지만 E 때문에 여전히 context switch와 cache에서의 손해를 보아야 한다. 그리고 이 작업을 single queue로 하기 위해서는 실제로 어떻게 돌아갈지는 정확하게는 모르겠지만 중간에 프로세스가 새로 들어왔을 때 정렬하는 비용도 발생을 할 것이다.
그러면 이제 queue의 개수, CPU, 프로세스의 개수를 바꾸어보자. CPU 2개에 4개의 프로세스가 작동을 한다고 해보자. 이때에는 어떻게 배치를 하는게 가장 좋을까? 아마도 ABCD 이렇게 섞이는 것보다는 AB, CD 이렇게 묶여서 각각의 CPU에서 교환이 되는것이 좋을 것이다. queue의 개수가 CPU만큼있다고 하면 이렇게 놓으면 쉽게 구현을 할 수 있을 것이다.

그런데, 위는 조금 이상적인 상황을 그려놔서 그러겠지만 만약에 작업하나가 끝났다고 생각을 해보자. C가 끝났다고 생각을 해보면 CPU0에서는 A만 돌아가고 CPU1에서는 B,D가 번갈아가며 돌아가고 자원할당이 다르게 일어난다.

거기에 심지어 A까지 끝났다고 생각을 해보면 이제 CPU0는 완전히 놀게 되고 CPU1은 열심히 Context switch와 cache 손해를 봐가면서 프로세스를 돌리게 된다. 공평하지도 않고 CPU0를 낭비하는 것은 손해이다.

그러면 이를 해결하기 위한 방법은 뭐가 있을까? 간단하다. B혹은 D를 CPU0로 보내주면 된다. 이를 Migration이라고 한다. 혹은 work stealing이라고 해서 일을 훔쳐온다고도 이야기를 한다. 아마 OS에서는 놀고 있는 CPU를 주기적으로 검사를 하고 일이 많은 CPU에 있는 프로세스 대기열을 쉬고 있는 CPU에게 전달을 해줄 것이다.

그러면 다음과 같은 그림처럼 프로세스 Scheduling이 일어나게 될 것이다. 이 과정에서는 CPU 사이에서의 데이터 교환을 하는 오버헤드도 발생할 것이고 하나의 프로세스 내에서의 Cache 이점, context switch 비용 모두 다 발생한다.
[ 왜 배우는 걸까? ]
사실 이 scheduler와 프로세스에 관한 개념을 통해 프로세스의 개수와 CPU 사이의 관계에 대해서 고민을 해보려고 글을 적었다. 그래서! Java로 이미지 변환하는 시간을 한번 멀티쓰레드 환경에서 측정을 해보려고 한다. 사실 udemy 강의에서 가져온 내용이긴한데 내 환경에서는 어떻게 되는지 한번 확인도 해볼겸 작성을 해본다.
우선 성능 측정을 하기 위해서는 내 PC의 환경부터 확인을 해야 한다. 예전에 데이터베이스 튜닝 실습을 할 떄에는 다음과 같은 양식으로 System setup을 작성했었다. 내 컴퓨터의 사양은 아래와 같다.

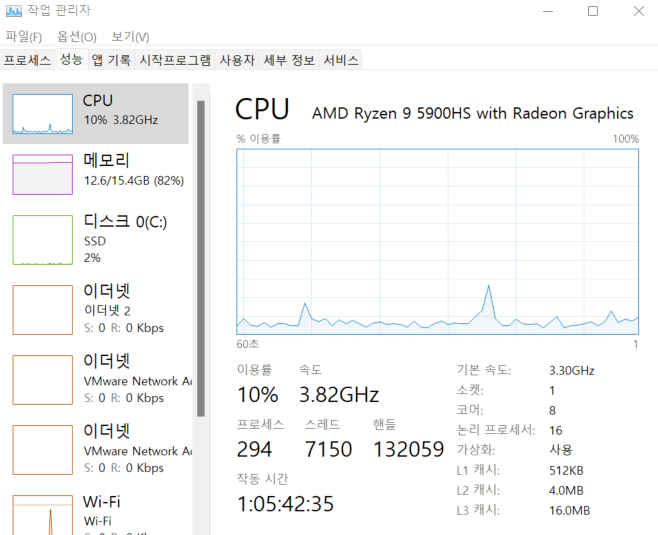
모든 정보는 제어판-> system -> 시스템 및 정보 칸에서 확인할 수 있다. 그리고 코어의 개수는 작업관리자 창에서 들어가서 확인할 수 있고 캐시별 크기도 확인할 수 있다.
그러면 해볼 일을 설명해보면, 이미지는 3036 x 4048 픽셀로 이루어진 이미지이다. 아래에 있는 해당 이미지를 보면 흰색 꽃과 보라색 꽃이 있다. 해당 이미지의 픽셀별로 색상 정보를 확인하여 만약 흰색이라면 보라색으로 변경하는 작업을 진행할 것이다. 싱글 쓰레드로 작업할 때에는 아래의 이미지 전체를 싱글 쓰레드가 변경하는 작업을 진행한다.
멀티 쓰레드 환경에서는 해당 이미지를 다음과 같이 섹터를 나누어 각각의 Thread에 할당을 한 뒤 작업한다. 아래의 경우는 4개의 쓰레드로 나눈 경우이며 주황색 줄로 영역 표시를 하였다.

성능 측정방식은 작업 후 시간에서 작업 전 시간을 뺴는 방식으로 진행을 했다. 우선 작업을 진행했을 때 3036 x 4048 픽셀 이미지를 기준으로 x축을 쓰레드의 개수, y축을 작업 종료시간으로 측정해보면 다음과 같은 결과가 나온다.

예상을 했을 때에는 모든 쓰레드 별로 CPU 코어 개수만큼 큐에 들어가 작업을 할 것이고 가상 코어까지 해서 10-12개쯤에서 가장 빨리 끝날 걸로 예상한만큼 떨어졌다. lock으로 묶어둔 공유 자원이 없어서 2에서 4로 넘어갈 때도 거의 절반으로 될 줄 알았는데 1에서 2로 갈 때만 크게 떨어지고 그 이후로는 조금씩 빠르게 끝났다. 이는 멀티 CPU 환경에서의 병렬성 덕분이지만 명확히 이렇게 줄어든 이유는 잘 모르겠다.
하지만 앞에서 설명한 내용들로 설명할 수 있는 것은 왜 쓰레드의 개수가 계속 늘어난다고 속도가 무한정 증가하지 않느냐이다. 그것은 CPU core 개수가 부족해서 동시에 돌릴 수 없기 떄문이다. 또한 scheduler의 입장에서 보면 오히려 cache 데이터를 날리고 context swiching으로 발생하는 오버헤드가 발생하고 쓰레드 scheduling 배치가 지저분해지기 떄문이다. 그래서 오히려 12부터는 10보단 처리시간이 길어지는 것을 볼 수 있다.
그렇다면 코어가 10개일 때 가장 빨리 끝났으니 이미지의 픽셀 개수를 낮춰서 작업을 한번 해보았다. 다음처럼 결과가 나왔고 당연히 작업할 양이 늘어날수록 완료시간은 늘어났다.

이 값으론 뭔가 작업 크기별 효율에 대해서는 잘 모르겠다. 그래서 픽셀의 개수와 시간의 관계에 대해서 고민을 해보았다. 픽셀 당 완료시간을 알면 좀 괜찮지 않을까 싶었다.
픽셀 당 완료 시간 = 완료시간 / 픽셀 수로 계산을 해본 결과 값은 다음과 같다.

결과는 다음과 같았다. 이 데이터를 통해서 알 수 있는 것은 작업의 크기가 클수록 멀티 쓰레드 환경에서 일에 대한 효율이 증가함을 알 수 있다. 그 이유는 쓰레드는 생성되는 시간이 있다. 그런데 작업이 작을수록 전체 일 대비 쓰레드 생성으로 낭비되는 시간의 비율이 커지기 때문이다.
이상으로 프로세스와 스케쥴러에 대한 포스팅을 마친다.